爬虫与反爬:使用Selenium+ChromeDriver抓取动态网页
本文介绍如何用Selenium抓取动态网页,包括Selenium+PhantomJS(已弃用)和Selenium+ChromeDriver。
1. 问题描述
最近想下载一些产品的图片(主图 + 细节图 + 穿搭图),https://www.urban-research.jp/product/rosso/bag/RA05-2AN007/,如下图所示(穿搭图在网页的下方):
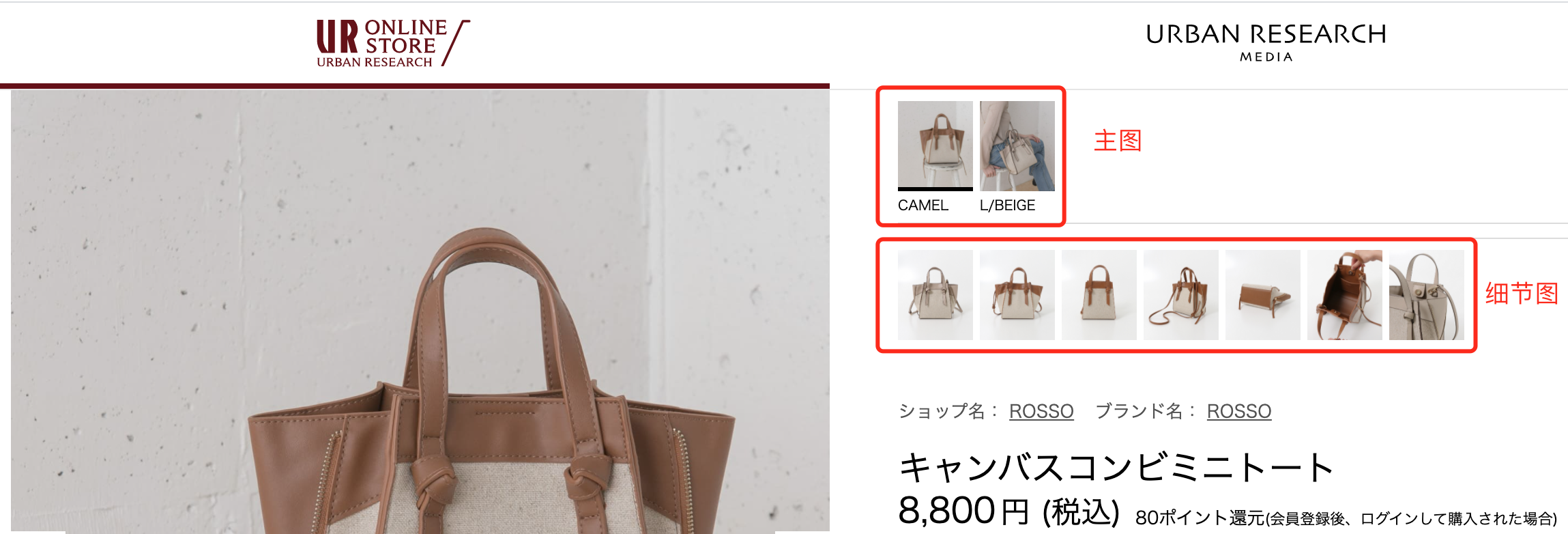 图1 欲抓取产品的主图、细节图
图1 欲抓取产品的主图、细节图
通过Chrome浏览器Inspect查看到对应的html代码如下:
<div class="dtl-l-SideR">
<div class="dtl-Mv_Thumbs">
<div class="dtl-Mv_ThumbColorArea">
/*** 主图 ***/
<div class="dtl-Mv_ColorWrap is-selected" data-all-id="0" data-color="760002" data-id="0">
<a href="javascript:void(0);" class="dtl-Mv_ColorItem" data-color="760002"><img src="/common/images/products/color/3/390903/2033720_base.jpg?20201216024457" alt=""></a><p>CAMEL</p>
</div>
<div class="dtl-Mv_ColorWrap" data-all-id="1" data-color="760001">
<a href="javascript:void(0);" class="dtl-Mv_ColorItem" data-color="760001"><img src="/common/images/products/color/3/390903/2033719_base.jpg?20201216024456" alt=""></a><p>L/BEIGE</p>
</div>
</div>
<div class="dtl-Mv_ThumbArea"></div>
<div class="dtl-Mv_ThumbFixArea">
/*** 详情图 ***/
<a href="javascript:void(0);" class="dtl-Mv_ThumbItem u-hover" data-all-id="2" data-color="-1" data-id="1">
<img src="/common/images/products/detail/3/390903/1795349_base.jpg" alt="">
</a>
<a href="javascript:void(0);" class="dtl-Mv_ThumbItem u-hover" data-all-id="3" data-color="-1" data-id="2"><img src="/common/images/products/detail/3/390903/1795351_base.jpg" alt="">
</a>
<a href="javascript:void(0);" class="dtl-Mv_ThumbItem u-hover" data-all-id="4" data-color="-1" data-id="3"><img src="/common/images/products/detail/3/390903/1795352_base.jpg" alt="">
</a>
<a href="javascript:void(0);" class="dtl-Mv_ThumbItem u-hover" data-all-id="5" data-color="-1" data-id="4"><img src="/common/images/products/detail/3/390903/1795353_base.jpg" alt="">
</a>
<a href="javascript:void(0);" class="dtl-Mv_ThumbItem u-hover" data-all-id="6" data-color="-1" data-id="5"><img src="/common/images/products/detail/3/390903/1795354_base.jpg" alt="">
</a>
<a href="javascript:void(0);" class="dtl-Mv_ThumbItem u-hover" data-all-id="7" data-color="-1" data-id="6"><img src="/common/images/products/detail/3/390903/1795355_base.jpg" alt="">
</a>
<a href="javascript:void(0);" class="dtl-Mv_ThumbItem u-hover" data-all-id="8" data-color="-1" data-id="7"><img src="/common/images/products/detail/3/390903/1795350_base.jpg" alt="">
</a>
</div>
</div>
然而,requests.get(url, headers=headers).text只返回简单的html代码,没有包含图片的url,如下:
<div class="dtl-l-SideR">
<div class="dtl-Mv_Thumbs">
<div class="dtl-Mv_ThumbColorArea"></div>
<div class="dtl-Mv_ThumbArea"></div>
<div class="dtl-Mv_ThumbFixArea"></div>
</div>
可见,这是一个动态网页。
浏览器通过HTTP(S)请求向服务器获取HTML,及包含在该HTML文件中的CSS、JS文件(实为源代码)。加载一个html文件,顺序加载并在加载过程中进行解析渲染。当加载过程遇到js文件,html文档会挂起渲染的线程,不仅要等文档中js文件加载完毕,还要等解析执行完毕,才可以恢复html文档的渲染线程
2. Selenium+PhantomJS抓取动态网页
抓取动态网页一个方法是从网页响应中找到js脚本返回的数据,做法可以参见另一篇博文:抓取由jQuery动态产生的网页数据:以东方财富中的沪港通历史数据为例。我在浏览器Inspect --> Network,没有找到对应的js脚本。
因此,换了另一个方法,用Selenium+PhantomJS。Selenium是一个Web自动化测试工具集,直接运行在浏览器中,就像真正的用户在操作一样,支持所有主流浏览器,IE、Firefox、Safari、Chrome、Opera、Edge。利用这一点,可以用Selenium来抓取网页。PhantomJS是一款无界面浏览器。上述抓取,可以用Selenium+PhantomJS来做。
- 安装Selenium:
pip install -U selenium - 安装PhantomJS:从官网下载,安装。如果是macOS,运行命令
brew tap homebrew/cask,bbrew install --cask phantomjs安装
抓取代码如下:
# Use Selenium+PhantomJS
from selenium import webdriver
from bs4 import BeautifulSoup
url = 'https://www.urban-research.jp/product/rosso/bag/RA05-2AN007/'
driver = webdriver.PhantomJS()
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml')
# Use requests
import requests
from bs4 import BeautifulSoup
url = 'https://www.urban-research.jp/product/rosso/bag/RA05-2AN007/'
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Mobile Safari/537.36'}
response = requests.get(url, headers=headers)
运行上述代码会给出PhantomJS已经弃用的警告:
Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead
于是,花了点时间,了解Selenium+ChromeDriver。
3. Selenium+ChromeDriver抓取动态网页
下载跟Chrome版本一致的ChromeDriver,在Chrome浏览器地址栏输入chrome://version/查看浏览器版本,比如我的是88.0.4324.96 (Official Build) (x86_64),可以在这里下载。下载后解压,将文件拷贝到/usr/local/bin/。
$ mv chromedriver /usr/local/bin/
使用Selenium+ChromeDriver抓取动态网页代码如下:
# Use Selenium+ChromeDriver
from selenium import webdriver
from bs4 import BeautifulSoup
url = 'https://www.urban-research.jp/product/rosso/bag/RA05-2AN007/'
# driver = webdriver.Chrome()
# 创建无界面的Chrome浏览器
opts = webdriver.ChromeOptions()
opts.headless = True
driver = webdriver.Chrome(options=opts)
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml')
值得注意的是,用Selenium+ChromeDriver抓取网页,最大的缺点是速度慢。
参考资料: