Downlolad Google's WebP Images via Take Screenshots with Selenium WebDriver
This post presents how to download Google's WebP images by capturing screenshots in Selenium WebDriver.
1. Problem Statement
I scrapy some pictures from an ecommerce website in common ways.
(1) Using [`requests.get(url, params=None, kwargs)`](https://2.python-requests.org/en/master/api/#requests.get)**:
import requests
import os
from urllib.parse import urlparse
def main():
url = 'https://image.rakuten.co.jp/azu-kobe/cabinet/hair1/hb-30-pp1.jpg'
filename = os.path.basename(urlparse(url).path)
response = requests.get(url)
with open(filename, "wb") as f:
f.write(response.content)
It works fine for a normal image, e.g., http://sparkandshine.net/wordpress/wp-content/uploads/2021/02/ABC_pay_qrcode.jpeg. However, it raised the error NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x10497ff70>: Failed to establish a new connection: [Errno 60] Operation timed out')) for https://image.rakuten.co.jp/azu-kobe/cabinet/hair1/hb-30-pp1.jpg as shown below.
response = requests.get(url)
File "/Users/sparkandshine/opt/anaconda3/lib/python3.8/site-packages/requests/api.py", line 76, in get
return request('get', url, params=params, **kwargs)
File "/Users/sparkandshine/opt/anaconda3/lib/python3.8/site-packages/requests/api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
File "/Users/sparkandshine/opt/anaconda3/lib/python3.8/site-packages/requests/sessions.py", line 530, in request
resp = self.send(prep, **send_kwargs)
File "/Users/sparkandshine/opt/anaconda3/lib/python3.8/site-packages/requests/sessions.py", line 643, in send
r = adapter.send(request, **kwargs)
File "/Users/sparkandshine/opt/anaconda3/lib/python3.8/site-packages/requests/adapters.py", line 516, in send
raise ConnectionError(e, request=request)
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='image.rakuten.co.jp', port=443): Max retries exceeded with url: /azu-kobe/cabinet/hair1/hb-30-pp1.jpg (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x10497ff70>: Failed to establish a new connection: [Errno 60] Operation timed out'))
(2) Using urllib.request.urlretrieve(url, filename=None, reporthook=None, data=None):
import urllib.request
import os
from urllib.parse import urlparse
url = 'https://image.rakuten.co.jp/azu-kobe/cabinet/hair1/hb-30-pp1.jpg'
filename = os.path.basename(urlparse(url).path)
urllib.request.urlretrieve(url, filename)
Note that the function is ported from the Python 2 module urllib (as opposed to urllib2). It might become deprecated at some point in the future.
It raised the error urllib.error.URLError: <urlopen error [Errno 60] Operation timed out> (The above code snippet works fine for a normal image.).
urllib.request.urlretrieve(url, filename)
File "/Users/sparkandshine/opt/anaconda3/lib/python3.8/urllib/request.py", line 247, in urlretrieve
with contextlib.closing(urlopen(url, data)) as fp:
File "/Users/sparkandshine/opt/anaconda3/lib/python3.8/urllib/request.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "/Users/sparkandshine/opt/anaconda3/lib/python3.8/urllib/request.py", line 525, in open
response = self._open(req, data)
File "/Users/sparkandshine/opt/anaconda3/lib/python3.8/urllib/request.py", line 542, in _open
result = self._call_chain(self.handle_open, protocol, protocol +
File "/Users/sparkandshine/opt/anaconda3/lib/python3.8/urllib/request.py", line 502, in _call_chain
result = func(*args)
File "/Users/sparkandshine/opt/anaconda3/lib/python3.8/urllib/request.py", line 1393, in https_open
return self.do_open(http.client.HTTPSConnection, req,
File "/Users/sparkandshine/opt/anaconda3/lib/python3.8/urllib/request.py", line 1353, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [Errno 60] Operation timed out>
2. Problem Analysis
I tried to download the image manually via Chrome using Save Image As, and got this:
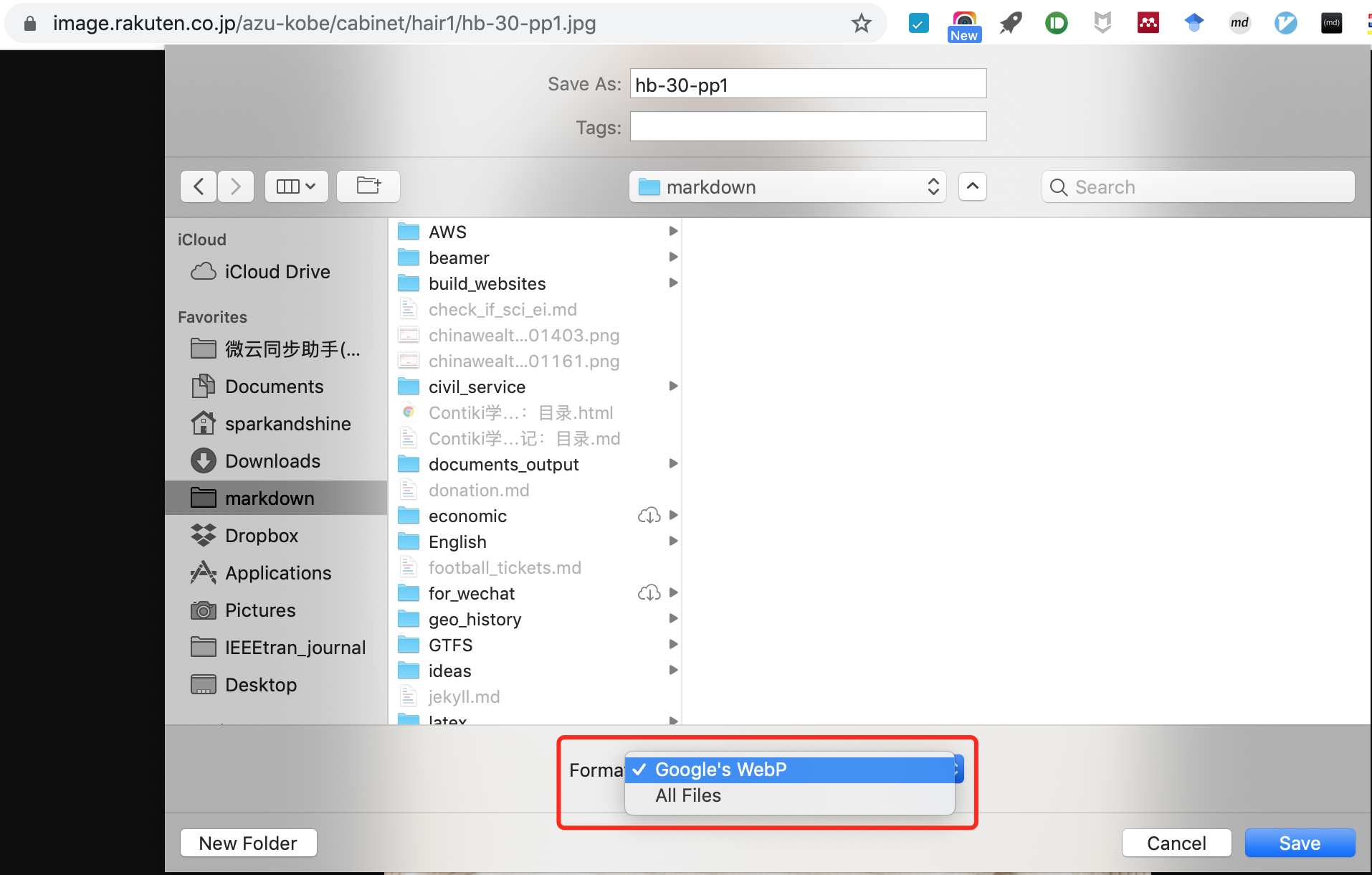 Figure 1 Save as an image on Chrome
Figure 1 Save as an image on Chrome
Oops, the format of the request image is Google's WebP, instead of common formats.
WebP is a modern image format that provides superior lossless and lossy compression for images on the web. WebP lossless images are 26% smaller in size compared to PNGs. WebP lossy images are 25-34% smaller than comparable JPEG images at equivalent SSIM quality index.
3. Download Google's WebP Images
I came up with a way to download WebP images: taking a screenshot with Selenium WebDriver, i.e., using driver.save_screenshot(filename). Note that the file extension must be .png.
from selenium import webdriver
import os
from urllib.parse import urlparse
url = 'https://image.rakuten.co.jp/azu-kobe/cabinet/hair1/hb-30-pp1.jpg'
filename = os.path.basename(urlparse(url).path)
filename_png = os.path.splitext(filename)[0] + '.png' # change file extension to .png
opts = webdriver.ChromeOptions()
opts.headless = True
driver = webdriver.Chrome(options=opts)
driver.get(url)
driver.save_screenshot(filename_png)
I got this,
 Figure 1 An image captured with Selenium
Figure 1 An image captured with Selenium
There are two black areas on both sides of the image. To get the right size image, we set the width and height of the current window before taking screenshots, using driver.set_window_size(width, height, windowHandle='current').
The width and height can be found from its HTML codes (Right click --> Inspect on Chrome).
<img style="-webkit-user-select: none;margin: auto;cursor: zoom-in;background-color: hsl(0, 0%, 90%);transition: background-color 300ms;" src="https://image.rakuten.co.jp/azu-kobe/cabinet/hair1/hb-30-pp1.jpg" width="517" height="673">
It is easy to extract them with the library BeautifulSoup. The complete codes are listed below.
from bs4 import BeautifulSoup
from selenium import webdriver
import os
from urllib.parse import urlparse
url = 'https://image.rakuten.co.jp/azu-kobe/cabinet/hair1/hb-30-pp1.jpg'
filename = os.path.basename(urlparse(url).path)
filename_png = os.path.splitext(filename)[0] + '.png' # change file extension to .png
opts = webdriver.ChromeOptions()
opts.headless = True
driver = webdriver.Chrome(options=opts)
driver.get(url)
# Get the width and height of the image
soup = BeautifulSoup(driver.page_source, 'lxml')
width = soup.find('img')['width']
height = soup.find('img')['height']
driver.set_window_size(width, height) # driver.set_window_size(int(width), int(height))
driver.save_screenshot(filename_png)
Done:-)
References
[1] urllib2 - Downloading a picture via urllib and python - Stack Overflow
[2] firefox - Download image with selenium python - Stack Overflow