第一个爬虫程序:建立联系方式表格
实验室网页通常会有研究者的信息(如姓名、办公室、研究组、电子邮件),而且格式规整。写了一个简单Python爬虫程序,将同事的联系信息爬下来,建立一张联系方式表格。
1. 概述
爬取同事的联系信息,思路很简单。首先,将每个人的页面url收集起来;其次,从每个人页面提取所需要信息。
2. 收集个人页面
庆幸的是,我想抓取的人都在项目组members里面,http://www.irit.fr/Members,531?lang=fr(注,该链接现在已经不可用了)。这样的话,我只要从该网页将个人页面的url提取出来就可以了。
用Chrome浏览器的Inspect element查看HTML文本,个人页面的url格式如下:
<li><a href=”[http://www.irit.fr/spip.php?page=annuaire&code=8955″](http://www.irit.fr/spip.php?page=annuaire&code=8955")>Qiankun Su</a>, Doctorant (<font class="stabilo"><i>co-encadrement</i></font> SC)
</li>
接下来从HTML文本提取个人页面超链接,将这些url收集起来,存在一个集合里。主要源代码如下:
def get_all_contact_urls(self):
base_url = 'http://www.irit.fr/Personnel,197?lang=fr'
try:
response = requests.get(base_url)
except (requests.exceptions.MissingSchema, requests.exceptions.ConnectionError):
return
soup = BeautifulSoup(response.text)
# retrieve links like: http://www.irit.fr/spip.php?page=annuaire&code=8292
for anchor in soup.find_all("a") :
if anchor.has_attr('href') :
link = anchor['href']
if 'annuaire&code' in link :
self.set_urls.add(link)
3. 从单个页面提取内容
经过上一步后,得到了一个包含个人页面的url集合,现在只需要遍历整个集合,从每个url提取所需要信息即可。源代码如下:
def crawler_contact_infos(self):
self.get_all_contact_urls()
header = ['Name', 'Statut', 'Service/Equipe', 'Contact', 'Localisation', 'Téléphone']
self.contact_infos.append(header)
for url in self.set_urls :
#url = 'http://www.irit.fr/spip.php?page=annuaire&code=8955&lang=fr'
record = self.crawler_contact_info(url)
self.contact_infos.append(record)
用Chrome浏览器的Inspect element查看HTML文本,了解联系信息是怎么组织的,如下图:
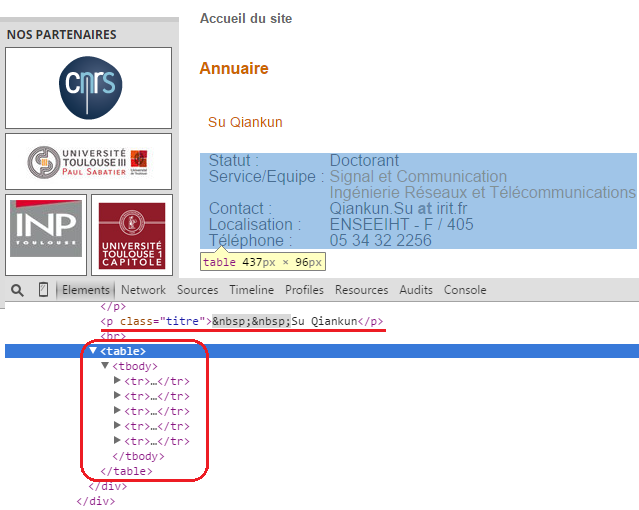
可见,联系信息由一个表格组织而成。将表格的信息提取出来组织成一条记录,如下:
def crawler_contact_info(self, url):
try:
response = requests.get(url)
except (requests.exceptions.MissingSchema, requests.exceptions.ConnectionError):
# ignore pages with errors
return list()
record = list()
soup = BeautifulSoup(response.text)
# Step 1: get the name
tags_name = soup.find_all("p", {"class" : "titre"}) #<p class="titre"> Su Qiankun</p>
if not tags_name: # deal with tags_name=[]
return record
name = tags_name[0].contents[0].strip() #strip() remove whitespace
record.append(name)
# Step 2: get other infos
table = soup.find('table')
# table_body = table.find('tbody')
for row in table.find_all('tr') :
rep = {ord(':'): ''} #remove ':' at the end of string, such as 'Statut : '
columns = [col.get_text().translate(rep).replace(' at ', '@').strip() for col in row.find_all('td')]
record.append(columns[1]) #store value
return record
完整的源代码在GitHub,在这里。
4. BeatifulSoup
BeatifulSoup安装如下:
# python2.x
sudo pip install BeautifulSoup4
# Python3
sudo apt-get install python3-bs4 #apt-cache search beautifulsoup