本文分析了Coffee文件系统读取文件cfs_read技术细节,包括FD_VALID、FD_READABLE、FILE_MODIFIED、absolute_offset、COFFEE_READ、COFFEE_MICRO、log_param、read_header、read_log_page、adjust_log_config、modify_log_buffer、get_record_index。cfs_read,当没有微日志文件时,cfs_read直接从原始文件读取,否则从微日志文件读取。
1. cfs_read
1.1 概述
cfs_read从打开文件fd读取数据,存放在buf,读取的字节数是size,返回实际读取的字节数。从预定义宏指令可以看出,cfs_read总体上包括两种情况:配置了微日志与没有配置微日志。但都必须进行参数验证。`cfs_read先进行参数验证(fd有效性、读取权限、size),而后再读取(无微日志文件的读和有微日志文件的读),源码如下:
int cfs_read(int fd, void *buf, unsigned size)
{
struct file_desc *fdp;
struct file *file;
#if COFFEE_MICRO_LOGS
struct file_header hdr;
struct log_param lp;
unsigned bytes_left;
int r;
#endif
/*****fd有效性检查及权限判断,见1.2********/
if (!(FD_VALID(fd) && FD_READABLE(fd)))
{
return - 1;
}
/********************************/
fdp = &coffee_fd_set[fd];
file = fdp->file;
/******size参数调整,见1.3********/
if (fdp->offset + size > file->end)
{
size = file->end - fdp->offset;
}
/******没有微日志文件读,见二***********/
if (!FILE_MODIFIED(file))
{
COFFEE_READ(buf, size, absolute_offset(file->page, fdp->offset));
fdp->offset += size;
return size;
}
/******有微日志文件读,见三***********/
#if COFFEE_MICRO_LOGS
read_header(&hdr, file->page);
for (bytes_left = size; bytes_left > 0; bytes_left -= r)
{
r = - 1;
lp.offset = fdp->offset;
lp.buf = buf;
lp.size = bytes_left;
r = read_log_page(&hdr, file->record_count, &lp);
if (r < 0)
{
COFFEE_READ(buf, lp.size, absolute_offset(file->page, fdp->offset));
r = lp.size;
}
fdp->offset += r;
buf = (char*)buf + r;
}
#endif
return size;
}
1.2 FD_VALID宏和FD_READABLE宏
(1)FD_VALID
FD_VALID宏用于判断cfs_read函数传进来的fd是否有效,不能小于0(如,-1是get_available_fd函数分配不到fd的返回值),也不能大于FD的上限(即COFFEE_FD_SET_SIZE),其对应的file_desc的标志flags不能为空闲(COFFEE_FD_FREE),源码如下:
#define FD_VALID(fd) ((fd)>=0 && (fd)<COFFEE_FD_SET_SIZE && coffee_fd_set[(fd)].flags!=COFFEE_FD_FREE)
(2)FD_READABLE
FD_READABLE宏用于打开的文件有读权限,源码如下:
#define FD_READABLE(fd) (coffee_fd_set[(fd)].flags & CFS_READ)
1.3 size参数调整
如果文件欲读取的字节数(size)超过文件末尾,则将读取字节数设为最大能读取的字节数(即最多只能读到文件末尾),源码如下:
if (fdp->offset + size > file->end)
{
size = file->end - fdp->offset;
}
2. 没有微日志的读
没有微日志情况下的读,略去参数验证及与本节无关代码如下:
struct file_desc *fdp;
struct file *file;
fdp = &coffee_fd_set[fd];
file = fdp->file;
if (!FILE_MODIFIED(file)) //判断该文件是否只是原始文件(意味着没有修改过,没有微日志文件),详情见2.1
{
COFFEE_READ(buf, size, absolute_offset(file->page, fdp->offset)); //absolute_offset见2.2,COFFEE_READ见2.3
fdp->offset += size; //更新偏移量
return size; //返回实际读写字节数
}
2.1 FILE_MODIFIED
file的flags只有两种取值:0和COFFEE_FILE_MODIFIED,将物理文件缓存时(load_file函数,详情见博文《打开文件cfs_open》2.5节),如果物理文件元数据file_header的flags的M位为1的话(即物理文件被修改,日志存在),则file->flags设为COFFEE_FILE_MODIFIED,否则设为0。部分代码如下:
//load_file函数部分代码
file->flags = 0;
if (HDR_MODIFIED(*hdr))
{
file->flags |= COFFEE_FILE_MODIFIED; //如果文件被修改(表示日志存在),#define COFFEE_FILE_MODIFIED 0x1
}
再看下面的代码就很清楚了,如果file->flags为COFFEE_FILE_MODIFIED,则返回真。
#define FILE_MODIFIED(file) ((file)->flags & COFFEE_FILE_MODIFIED)
#define COFFEE_FILE_MODIFIED 0x1
2.2 absolute_offset
absolute_offset函数返回文件系统的绝对偏移量(但不是物理偏移量),得出的是从COFFEE_START处的偏移量,而不是从FLASH开始外的偏移量,因为COFFEE_START往往不等于FLASH_START(因为会拿出FLASH一部分空间用于存放代码,不受文件系统管理)。absolute_offset源码如下:
//absolute_offset(file->page, fdp->offset)
static cfs_offset_t absolute_offset(coffee_page_t page, cfs_offset_t offset)
{
return page *COFFEE_PAGE_SIZE + sizeof(struct file_header) + offset;
}
2.3 COFFEE_READ宏
COFFEE_READ宏直接定位到硬件相关的读函数,移植Coffee文件的时候需要映射过去(在cfs-coffee-arch.h),源码如下:
#define COFFEE_READ(buf, size, offset) stm32_flash_read(COFFEE_START+offset, buf, size)
COFFEE_READ与stm32_flash_read映射关系如下图,在原有的offset加上COFFEE_START,就得到了从FLASH_START处的偏移量,即实际物理FLASH位置。
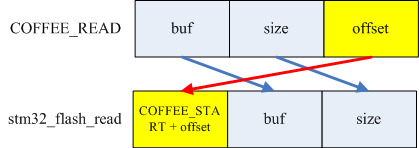
图1 COFFEE_READ与stm32_flash_read映射关系
3. 有微日志文件的读取
有微日志情况下的读,略去参数验证及与本节无关代码如下:
//int cfs_read(int fd, void *buf, unsigned size)
struct file_desc *fdp;
struct file *file;
#if COFFEE_MICRO_LOGS //见3.1
struct file_header hdr;
struct log_param lp; //见3.2
unsigned bytes_left;
int r;
#endif
fdp = &coffee_fd_set[fd];
file = fdp->file;
#if COFFEE_MICRO_LOGS
read_header(&hdr, file->page); //读取物理文件的元数据file_header,见3.3
/*如果微日志文件有数据,直接从微日志文件读取数据,否则从原始文件读取*/
for (bytes_left = size; bytes_left > 0; bytes_left -= r) //读取日志记录,当size跨越多个日志记录时,则需要逐个记录读取
{
r = - 1;
/*初始化结构体log_param类型的lp*/
lp.offset = fdp->offset;
lp.buf = buf;
lp.size = bytes_left;
r = read_log_page(&hdr, file->record_count, &lp); //见四
/*如果在微日志文件找不到数据,就直接从原始文件读取*/
if (r < 0)
{
COFFEE_READ(buf, lp.size, absolute_offset(file->page, fdp->offset)); //详情见1.3
r = lp.size;
}
fdp->offset += r;
buf = (char*)buf + r;
}
#endif
return size;
3.1 COFFEE_MICRO_LOGS
微日志是Coffee文件系统的一大亮点,当文件需要修改时,创建微日志结构并链接到原始文件,而不是创建新的文件。系统默认是配置微日志,源码如下:
#ifndef COFFEE_MICRO_LOGS
#define COFFEE_MICRO_LOGS 1
#endif
不过也可以不配置微日志,在cfs_coffee_arch.h文件将COFFEE_MICRO_LOGS定义为0,如下:
#define COFFEE_MICRO_LOGS 0
3.2 log_param
在Google搜没找到buggy compiler相关资料,不晓得是什么东西。通过源码分析,当欲读取大小跨越两个日志记录(甚至更多)时,log_param用于辅助分开读取,即先读前一个日志记录包含的内容,再读取后一个日志记录包含的内容。源码如下:
/* This is needed because of a buggy compiler. */
struct log_param
{
cfs_offset_t offset;
const char *buf;
uint16_t size;
};
3.3 read_header
read_header将物理文件的元数据file_header读出来放在hdr结构体,源代码如下:
static void read_header(struct file_header *hdr, coffee_page_t page)
{
COFFEE_READ(hdr, sizeof(*hdr), page *COFFEE_PAGE_SIZE);
#if DEBUG
if (HDR_ACTIVE(*hdr) && !HDR_VALID(*hdr))
{
PRINTF("Invalid header at page %u!\n", (unsigned)page);
}
#endif
}
4. read_log_page
read_log_page将日志记录读到lp->buffer中,返回实际读取的大小lp->size。首先检查一些参(log_record_size、log_records、search_records),必要时进行一些调整,而后求得欲读取位置对应的索引表项,进而求得偏移量,最后调用COFFEE_READ读取数据。源代码如下:
//r = read_log_page(&hdr, file->record_count, &lp);
#if COFFEE_MICRO_LOGS
static int read_log_page(struct file_header *hdr, int16_t record_count, struct log_param *lp)
{
uint16_t region;
int16_t match_index;
uint16_t log_record_size;
uint16_t log_records;
cfs_offset_t base;
uint16_t search_records;
adjust_log_config(hdr, &log_record_size, &log_records); //若log_record_size和log_records为0,则设成默认值,详情见4.1
region = modify_log_buffer(log_record_size, &lp->offset, &lp->size); //设置offset,必要时调整size,返回region,见4.2
search_records = record_count < 0 ? log_records : record_count; //需要搜索的记录数,record_count是file的成员变量
match_index = get_record_index(hdr->log_page, search_records, region); //见4.3
if (match_index < 0)
{
return - 1;
}
/***求出文件欲读取的Coffee偏移量(即从COFFEE_START开始处的偏移量),见4.5***/
base = absolute_offset(hdr->log_page, log_records *sizeof(region)); //索引表大小
base += (cfs_offset_t)match_index *log_record_size; //跳过match_index个记录
base += lp->offset;
COFFEE_READ(lp->buf, lp->size, base);
return lp->size;
}
#endif
4.1 adjust_log_config
在博文《文件组织及若干数据结构》分析结构体file_header成员变量log_record_size,说如果该项为0,则会被设成默认值(即COFFEE_PAGE_SIZE),就是在这里设置的。log_records表示日志可以容纳的记录数量(log records denotes the number of records that the log can hold),如果该项为0,则设成(COFFEE_LOG_SIZE)/(*log_record_size)。
//adjust_log_config(hdr, &log_record_size, &log_records);
#if COFFEE_MICRO_LOGS
static void adjust_log_config(struct file_header *hdr, uint16_t *log_record_size, uint16_t *log_records)
{
*log_record_size = hdr->log_record_size == 0 ? COFFEE_PAGE_SIZE : hdr->log_record_size;
*log_records = hdr->log_records == 0 ? COFFEE_LOG_SIZE / *log_record_size: hdr->log_records;
}
#endif
4.2 modify_log_buffer
modify_log_buffer将偏移量(全局的)调整为日志记录内部的偏移量,如果欲读取的大小跨越两个日志记录(甚至更多),则需调整size为从offset到第一日志记录末尾,最后返回region。modify_log_buffer函数示意图如下:
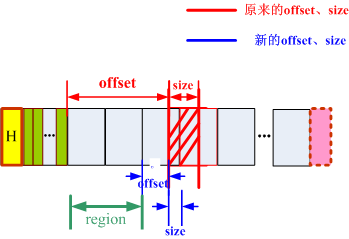
图2 modify_log_buffer函数示意图
modify_log_buffer源代码如下:
//region = modify_log_buffer(log_record_size, &lp->offset, &lp->size),其中lp.offset被初始化为fdp->offset
#if COFFEE_MICRO_LOGS
static uint16_t modify_log_buffer(uint16_t log_record_size, cfs_offset_t *offset, uint16_t *size)
{
uint16_t region;
region = *offset / log_record_size; //算出从第几个region开始
*offset %= log_record_size;
if (*size > log_record_size - *offset) //当size跨越两个(甚至更多)日志记录时,需调整size
{
*size = log_record_size - *offset;
}
return region;
}
#endif
4.3 log_records & record_count & search_records
log_records是file_header的成员变量,表示日志可以容纳的记录数量(log records denotes the number of records that the log can hold)。如果为0,会自动调节成COFFEE_LOG_SIZE/*log_record_size,而log_record_size若为0,则会自动调成成COFFEE_PAGE_SIZE,这些是在adjust_logo_config函数完成的(见4.1)。
record_count是file的成员变量,表示文件实际的日志记录数量,加载文件load_file将record-count设为-1(源码注释-We don't know the amount of records yet)。
search_records是read_log_page函数定义的一个成员变量,表示需要搜索的记录数,若已有record_count值,则用record_count初始化search_records,否则用log_records,源码如下:
//static int read_log_page(struct file_header *hdr, int16_t record_count, struct log_param *lp)
search_records = record_count < 0 ? log_records : record_count;
4.4 get_record_index
get_record_index求得region日志记录对应的索引表项,源代码如下:
//match_index = get_record_index(hdr->log_page, search_records, region);
#if COFFEE_MICRO_LOGS
static int get_record_index(coffee_page_t log_page, uint16_t search_records, uint16_t region)
{
cfs_offset_t base;
uint16_t processed;
uint16_t batch_size;
int16_t match_index, i;
base = absolute_offset(log_page, sizeof(uint16_t) *search_records); //返回索引表最后一个字节处,见4.4.1
batch_size = search_records > COFFEE_LOG_TABLE_LIMIT ? COFFEE_LOG_TABLE_LIMIT: search_records; //调整search_records,不能超过COFFEE_LOG_TABLE_LIMIT
processed = 0; //正在读取的记录
match_index = - 1;
{
uint16_t indices[batch_size]; //存放索引表
while (processed < search_records && match_index < 0)
{
if (batch_size + processed > search_records) //调整batch_size大小,不能超过search_records
{
batch_size = search_records - processed;
}
base -= batch_size * sizeof(indices[0]); //base从索引表末尾移到索引表开始处,见4.4.1
COFFEE_READ(&indices, sizeof(indices[0]) *batch_size, base); //读取索引表放入indices[batch_size],见4.4.1
for (i = batch_size - 1; i >= 0; i--) //索引表从后向前扫描
{
/***索引表项正好指向region记录(即找到索引表项),返回match_index***/
if (indices[i] - 1 == region)
{
match_index = search_records - processed - (batch_size - i);
break;
}
}
processed += batch_size;
}
}
return match_index; //没找到region日录对应的索引项,则返回-1
}
#endif
读取索引表
通过absolute_offset求得索引表末尾位置base(如下图红色箭头所示),再通过base -= batch_size * sizeof(indices[0])求得索引表开始位置(如下图绿色箭头所示),最后通过COFFEE_READ将索引表读入indices[]数组。整个过程示意图如下:
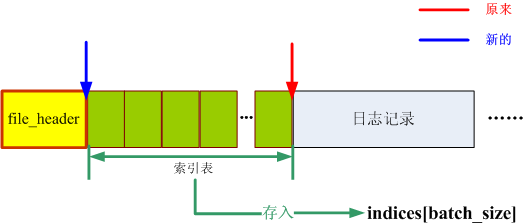
图3 读取索引表示意图
4.5 read_log_page中求偏移量
得到文件欲读取的索引表项后,接下来,求得偏移量(从COFFEE_START开始处的偏移量),结合源码和下图理解,很快就会懂的,如下:
base = absolute_offset(hdr->log_page, log_records *sizeof(region)); //索引表大小
base += (cfs_offset_t)match_index *log_record_size; //跳过match_index个记录
base += lp->offset;
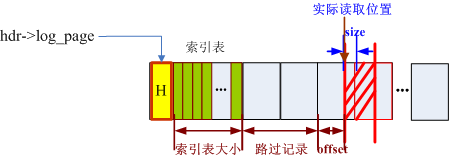
图4 read_log_page求偏移量示意图
上述图1-4源文件如下: