本文深入源码分析Coffee文件系统打开文件cfs_open函数技术细节,包括flags、get_available_fd、file_end、find_file、FILE_FREE、read_header、next_file、load_file。
1. cfs_open
cfs_open用于打开一个文件,成功打开返回文件描述符fd,否则返回-1。如果文件不存在,则试图创建新文件。cfs_open首先获得最小未使用的文件描述符fd(若没有可用的fd,则返回-1),而后查看文件是否已缓存并且对应物理文件有效,若是则打开成功。若物理上没有该文件,则试图创建。值得注意的是,即便文件创建成功也可能返回-1(当coffee_files[COFFEE_MAX_OPEN_FILES]数组没有可用项时)。
cfs_open算法流程图如下:

图1 cfs_open算法流程
cfs_open源代码如下:
int cfs_open(const char *name, int flags) //flags见1.1
{
int fd;
struct file_desc *fdp;
fd = get_available_fd(); //获得最小可用的fd,见1.2
if (fd < 0)
{
PRINTF("Coffee: Failed to allocate a new file descriptor!\n");
return -1;
}
fdp = &coffee_fd_set[fd];
fdp->flags = 0; //此处的0表示COFFEE_FD_FREE,源码#define COFFEE_FD_FREE 0x0
fdp->file = find_file(name); //寻找name对应的文件(不存在、在物理FLASH但没缓存、缓存),见二
/***没有name对应的文件,则试图创建新文件,见1.3***/
if (fdp->file == NULL)
{
if ((flags &(CFS_READ | CFS_WRITE)) == CFS_READ) //若flags是001或101,则返回-1
{
return - 1;
}
fdp->file = reserve(name, page_count(COFFEE_DYN_SIZE), 1, 0);
if (fdp->file == NULL)
{
return - 1;
}
fdp->file->end = 0; //新创建的空文件,文件末尾自然是0
}
/*file不为NULL(即找到文件并缓存),寻找文件末尾位置*/
else if (fdp->file->end == UNKNOWN_OFFSET) //找到文件末尾的位置,见1.4
{
fdp->file->end = file_end(fdp->file->page);
}
fdp->flags |= flags;
fdp->offset = flags &CFS_APPEND ? fdp->file->end: 0; //如果文件打开方式是追加APPEND,则将文件偏移量offset设到文件末尾,否则设成0
fdp->file->references++; //文件引用次数加1
return fd;
}
1.1 flags
flags表示文件是以什么(只读、写、追加)打开,源码如下(在contiki/core/cfs/cfs.h):
#ifndef CFS_READ
#define CFS_READ 1
#endif
#ifndef CFS_WRITE
#define CFS_WRITE 2
#endif
#ifndef CFS_APPEND
#define CFS_APPEND 4
#endif
可以单独设CFS_READ、CFS_WRITE、CFS_APPEND其中的一个,也可以用或(即|)连接设置多个flags(如CFS_READ | CFS_APPEND)。设置了CFS_APPEND意味着CFS_WRITE已被设置(注1),即从文件末尾写。如果设置CFS_WRITE而没有设置CFS_APPEND,则文件被截断(truncate)为0,即文件大小为0了[2](这点跟Linux不同)。
注1:尽管ContikiWiki[2],指出设置了CFS_APPEND意味着CFS_WRITE也被设置了,最近在分析写入文件cfs_write,发现情况并非如此。必须指定CFS_WRITE才能进行写,详情见博文《写入文件cfs_write》,部分源码如下:
if(!(FD_VALID(fd) && FD_WRITABLE(fd)))
{
return - 1;
}
#define FD_WRITABLE(fd) (coffee_fd_set[(fd)].flags & CFS_WRITE)
1.2 get_available_fd
类似于Linux,所有打开文件都通过文件描述符fd引用,函数get_available_fd返回最小未使用的描述符(即缓存file_desc数组coffee_fd_set[]首个flags为COFFEE_FD_FREE),没有可用的fd则返回-1。源码如下:
static int get_available_fd(void)
{
int i;
for (i = 0; i < COFFEE_FD_SET_SIZE; i++)
{
if (coffee_fd_set[i].flags == COFFEE_FD_FREE)
{
return i;
}
}
return - 1;
}
Coffee将文件描述符file_desc组织成一个数组,作为protected_mem_t的一个成员变量,系统缓存file_desc示意图如下,详情见博文《文件组织及若干数据结构》。
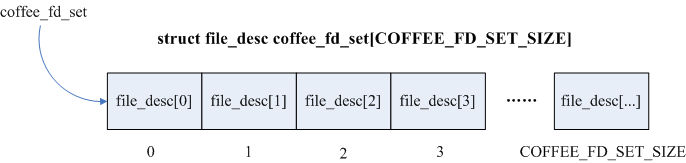
图2 Coffee缓存file_desc示意图
1.3 创建文件
执行find_file函数,若name对应的文件file还驻留在内存(即是否还在coffee_files[COFFEE_MAX_OPEN_FILES]数组里),并且对应的物理文件是有效的,则直接返回file,否则扫描整个FLASH,将name对应文件file(在FLASH中但没缓存)缓存到内存(这一步得确保coffee_files数组有可用的项,否则返回空NULL,参见load_file函数)。如果FLASH没有name对应的文件,也返回NULL。显然,这里要处理的情况是后者,则试图创建之。
首先检查cfs_open参数flags,若flags是001(CFS_READ)或101(CFS_APPEND|CFS_READ),则返回-1,即创建不成功。否则调用reserve为其分配新页面,并对file_header作一些设置。其中page_count(COFFEE_DYN_SIZE)求得COFFEE_DYN_SIZE字节需要分配多少Coffee页(因为还要包括file_header大小且需考虑页对齐)。详情见博文《创建文件》。
1.4 找到文件末尾位置file_end
find_file(const char *name),如果name对应的文件没有被缓存或者是缓存了但物理文件失效,则调用load_file将对应的物理FLASH文件缓存到RAM(物理上有这个文件且coffee_files有可用的项),此时file_end是UNKNOWN_OFFSET。因为Coffee没有在file_header存储文件末尾的位置(因为文件长度经常改变,加之FLASH先擦后写特性),所以打开一个文件时必须找到文件末尾的位置。
如图2所示,cfs_offset_t file_end从文件的最后一页max_pages-1往前找,直到找到空字节(即0x00),就找到file_end了,否则返回0。返回0有两种情况,一种是
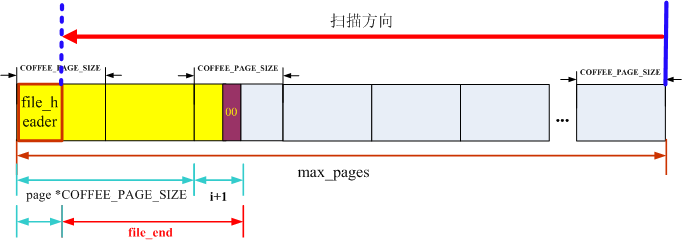
图3 file_end函数示意图
file_end源代码如下:
//fdp->file->end = file_end(fdp->file->page);
static cfs_offset_t file_end(coffee_page_t start)
{
struct file_header hdr;
unsigned char buf[COFFEE_PAGE_SIZE];
coffee_page_t page;
int i;
read_header(&hdr, start); //读取文件头file_header
/* An important implication of this is that if the last written bytes are zeroes, then these are skipped from the calculation.*/
for (page = hdr.max_pages - 1; page >= 0; page--) //从文件最后一页(预留的页而不是实际占有)往前找
{
COFFEE_READ(buf, sizeof(buf), (start + page) *COFFEE_PAGE_SIZE); //将Coffee页读入buf
for (i = COFFEE_PAGE_SIZE - 1; i >= 0; i--)
{
if (buf[i] != 0)
{
if (page == 0 && i < sizeof(hdr)) //没必要检查file_header
{
return 0;
}
return 1+i + (page *COFFEE_PAGE_SIZE) - sizeof(hdr);
}
}
}
return 0; //All bytes are writable
}
2. find_file
find_file函数用于找到文件名name对应的file指针。若name对应的文件file是还驻留在内存(即还在coffee_files[COFFEE_MAX_OPEN_FILES]数组里),并且对应的物理文件是有效的,则直接返回file指针,否则扫描整个FLASH,将name对应文件file(在FLASH中但没缓存)缓存到内存(这一步得确保coffee_files数组有可用的项,否则返回空NULL,参见load_file函数)。file可以理解成是file_header的缓存,但不等同(可参见博文《文件组织及若干数据结构》)。源代码如下:
static struct file *find_file(const char *name)
{
int i;
struct file_header hdr;
coffee_page_t page;
/*首先检查name对应的文件file是否还驻留在内存(是否缓存了file_header),即是否还在coffee_files[COFFEE_MAX_OPEN_FILES]数组里,若有,则直接返回file*/
for (i = 0; i < COFFEE_MAX_OPEN_FILES; i++) //遍历整个coffee_files[COFFEE_MAX_OPEN_FILES]数组
{
/*若没有max_pages不为0的文件file,则扫描整个FLASH(即跳出for循环,执行后面内容)*/
if (FILE_FREE(&coffee_files[i])) //file的max_pages是否为0,见2.1
{
continue;
}
/*如果找到了RAM缓存的file数组coffee_files[COFFEE_MAX_OPEN_FILES]中有空闲的项*/
read_header(&hdr, coffee_files[i].page); //读取文件的元数据,即file_header,详情见2.2
if (HDR_ACTIVE(hdr) && !HDR_LOG(hdr) && strcmp(name, hdr.name) == 0) //通过文件头file_header判断物理文件是否有效,见2.3
{
return &coffee_files[i];//文件元数据file_header被缓存且物理文件有效,则直接返回file
}
}
/*否则顺序扫描整个FLASH(没有缓存该文件file)*/
for (page = 0; page < COFFEE_PAGE_COUNT; page = next_file(page, &hdr))//next_file见2.4
{
read_header(&hdr, page);
if (HDR_ACTIVE(hdr) && !HDR_LOG(hdr) && strcmp(name, hdr.name)==0) //见2.3
{
return load_file(page, &hdr); //见2.5
}
}
return NULL; //如果物理FLASH没有该name对应的文件,也返回NULL
}
典型的情况,系统启动后,第一次打开文件,Coffee文件系统需要顺序扫描整个FLASH,因为Coffee格式化将coffee_files[COFFEE_MAX_OPEN_FILES]数组的结构成员变量都初始化为0(当然也包括max_pags),详情见博文《格式化cfs_coffee_format》。
2.1 FILE_FREE
max_pages是file的成员变量,用来表示文件预设的最大页面数(所有的Coffee文件创建时都会被预先设置)。在Coffee格式化时(参见博文《格式化cfs_coffee_format》),max_pages被置为0。当删除一个文件cfs_remove时,max_pages也被置为0。
#define FILE_FREE(file) ((file)->max_pages == 0)
2.2 read_header
read_header用于读取物理文件的元数据(即file_header),源码如下:
static void read_header(struct file_header *hdr, coffee_page_t page)
{
COFFEE_READ(hdr, sizeof(*hdr), page *COFFEE_PAGE_SIZE);
#if DEBUG
if (HDR_ACTIVE(*hdr) && !HDR_VALID(*hdr))
{
PRINTF("Invalid header at page %u!\n", (unsigned)page);
}
#endif
}
宏COFFEE_READ直接映射到平台相关的FLASH读函数(如stm32_flash_read),从offset处读取size字节存放到buf。其中offset是指从文件系统管理的FLASH处(即COFFEE_START,因为有些NOR FLASH将一部分空间用于存放代码)开始算的偏移量。
#define COFFEE_READ(buf, size, offset) stm32_flash_read(COFFEE_START+offset, buf, size)
void stm32_flash_read(u32_t address, void *data, u32_t length)
{
u8_t *pdata = (u8_t*)address;
ENERGEST_ON(ENERGEST_TYPE_FLASH_READ);
memcpy(data, pdata, length);
ENERGEST_OFF(ENERGEST_TYPE_FLASH_READ);
}
2.3 file_header的flags
文件头file_header(文件的元数据)的flags,为方便操作,Coffee将这些flags单独定义成宏,源码如下,各个标志位的含义见博文《 文件组织及若干数据结构 》。
/* File header flags. */
#define HDR_FLAG_VALID 0x1 /* Completely written header. */
#define HDR_FLAG_ALLOCATED 0x2 /* Allocated file. */
#define HDR_FLAG_OBSOLETE 0x4 /* File marked for GC. */
#define HDR_FLAG_MODIFIED 0x8 /* Modified file, log exists. */
#define HDR_FLAG_LOG 0x10 /* Log file. */
#define HDR_FLAG_ISOLATED 0x20 /* Isolated page. */
Coffee定义了若干宏来判断文件的状态(依据file_header中的flags),如下:
/* File header macros. */
#define CHECK_FLAG(hdr, flag) ((hdr).flags & (flag))
#define HDR_VALID(hdr) CHECK_FLAG(hdr, HDR_FLAG_VALID) //若V标志置1,则返回真
#define HDR_ALLOCATED(hdr) CHECK_FLAG(hdr, HDR_FLAG_ALLOCATED) //若A标志置1,则返回真
#define HDR_OBSOLETE(hdr) CHECK_FLAG(hdr, HDR_FLAG_OBSOLETE) //若O标志置1,则返回真
#define HDR_MODIFIED(hdr) CHECK_FLAG(hdr, HDR_FLAG_MODIFIED) //若M标志置1,则返回真
#define HDR_LOG(hdr) CHECK_FLAG(hdr, HDR_FLAG_LOG) //若L标志置1,则返回真
#define HDR_ISOLATED(hdr) CHECK_FLAG(hdr, HDR_FLAG_ISOLATED) //若I标志置1,则返回真
#define HDR_FREE(hdr) !HDR_ALLOCATED(hdr) //若A标志置0,则返回真
#define HDR_ACTIVE(hdr) (HDR_ALLOCATED(hdr) && !HDR_OBSOLETE(hdr) && !HDR_ISOLATED(hdr))//若A为1,O为0,I为0,则返回真
从以上分析可以看出,(HDR_ACTIVE(hdr) && !HDR_LOG(hdr) && strcmp(name, hdr.name)==0)含义就是文件正在使用(A),并且不是孤立(I)和无效(O)页,微日志文件没有被修改(?),且文件名相同,只有这样该文件的元数据才算被缓存,够复杂的吧:-) 事实上,就是判断物理文件有效性。考虑这样的情况(RAM确实缓存了文件元数据file_header,但物理文件已失效),写入文件数据超过文件预留的大小,此时,Coffee会新建一个文件,将原始文件和微日志文件拷贝到新文件,并将原来的文件标记为失效。
2.4 next_file函数
Coffee用快速跳跃(quick-skip)算法,快速跳过空闲的区域,以快速寻找下一个文件。算法最坏情况是遇到多个长连续的孤立页(multiple long sequences of isolated pages),但这种情况并不常见[3]。源码如下:
static coffee_page_t next_file(coffee_page_t page, struct file_header *hdr)
{
if (HDR_FREE(*hdr))
{
return (page + COFFEE_PAGES_PER_SECTOR) &~(COFFEE_PAGES_PER_SECTOR - 1);
}
else if (HDR_ISOLATED(*hdr))
{
return page + 1;
}
return page + hdr->max_pages;
}
2.5 load_file
load_file将文件的元数据file_header缓存到RAM的file,如果能在coffee_files[COFFEE_MAX_OPEN_FILES]数组中找到可用项(即是否有文件file的max_pages为0或者引用次数为0的项),就缓存,否则返回空NULL。源代码如下:
static struct file *load_file(coffee_page_t start, struct file_header *hdr)
{
int i, unreferenced, free;
struct file *file;
/*首先检查内存是否缓存了file,即是否在coffee_files[COFFEE_MAX_OPEN_FILES]数组中*/
for (i = 0, unreferenced = free = - 1; i < COFFEE_MAX_OPEN_FILES; i++) //遍历整个coffee_files[COFFEE_MAX_OPEN_FILES]数组
{
/*试图从coffee_files[COFFEE_MAX_OPEN_FILES]数组找到第一个max_pages为0的file(表示该项空闲,可使用)*/
if (FILE_FREE(&coffee_files[i]))
{
free = i;
break;
}
/*退而求其次,查看coffee_files[COFFEE_MAX_OPEN_FILES]数组是否有引用次数为0的项*/
else if (FILE_UNREFERENCED(&coffee_files[i]))
{
unreferenced = i;
}
}
/*如果coffee_files[COFFEE_MAX_OPEN_FILES]数组中的file,即没有max_pages为0,也没有引用次数为0的,那么就返回空*/
if (free == - 1)
{
if (unreferenced != - 1)
{
i = unreferenced;
}
else
{
return NULL;
}
}
/*将物理上文件的file_header(存放在文件的开始处)缓存到内存的file*/
file = &coffee_files[i];
file->page = start;
file->end = UNKNOWN_OFFSET; //因为文件大小经常变化,所以在file_header不存储文件末尾位置
file->max_pages = hdr->max_pages;
file->flags = 0;
if (HDR_MODIFIED(*hdr))
{
file->flags |= COFFEE_FILE_MODIFIED; //如果文件被修改(表示日志存在),#define COFFEE_FILE_MODIFIED 0x1
}
file->record_count = - 1; //此时还不知道日志数量
return file;
}
FILE_UNREFERENCED宏定义如下,即判断文件引用次数是否为0,源代码如下:
#define FILE_UNREFERENCED(file) ((file)->references == 0)
HDR_MODIFIED宏,源代码如下:
#define HDR_MODIFIED(hdr) CHECK_FLAG(hdr, HDR_FLAG_MODIFIED)
#define CHECK_FLAG(hdr, flag) ((hdr).flags & (flag))
莫非内存file的flags与file_header的flags各位含义不同???源码如下:
#define COFFEE_FILE_MODIFIED 0x1
#define HDR_FLAG_MODIFIED 0x8
上文图1~3的源文件如下:
参考资料:
[1] Enabling Large-Scale Storage in Sensor Networks with the Coffee File System.pdf
[2] Contiki Wiki
[3] Contiki源代码